Bachelor Thesis
Back in 2022 I was in my final year of Bachelor’s Degree and it was time to pick up a topic for my thesis. Like most students, I didn’t really have any vision… I was scrolling through the topics list and spotted one that piqued my interest - Improving User Experience on the Web. It was a little vague, but it meant there was some opportunity for choosing the direction. My supervisor asked me during our meeting what sort of topics I liked, and I mentioned I’m interested in natural language processing. He gave me a great suggestion, and suddenly, I had a vision.
Sentiment Analysis
The core of the thesis was an experiment, which consisted of analyzing speech of the participants (during usability testing) and determining the usability problems (or positives) on a website, using sentiment analysis. The experiment evaluated the website using user testing methods, such as remote unmoderated testing with think-aloud protocol. We opted for rules-based lexicon to obtain the sentiment analysis. Normally these days, it would be pretty common to use machine learning for sentiment analysis, but since we didn’t think the domain of UX was very developed for this method, we opted for rules-based analysis.
Sentiment analysis on its own is a very interesting topic with many nuances. It is quite fascinating how far we’ve come with LLMs and many of the problems I faced back in 2022 have been solved by now. Some of them are comparative sentences (“The camera is good, but I think I prefer iPhone’s camera”), negated sentences and which words are affected by the negation (but there are also implicit negations, such as “… it avoids suspense, which we can find in Hollywood movies…“), implicit opinions (“I returned the phone after two days”), sarcasm - sometimes difficult to understand even for humans (“All the good features that you want! Too bad they’re not working.”), coreferences, words with multiple meanings, and noisy text with mistakes or slang. One more thing I mentioned in my thesis was the lack of support in other languages, which back then was usually solved by translating the text into English, and then performing sentiment analysis on the English text. However there has been a lot of improvement in NLP for many languages as well.
In standard NLP process, we go through several stages to prepare the text for analysis. This usually includes:
- data cleaning (removing special characters, etc)
- tokenization
- POS tagging
- stemming or lemmatization
- stop-words removal
This was done using Python, mainly the nltk library. For analysis, we used JupyterLab, since it is a good environment suitable for such tasks.
User Testing
User experience (UX) encompasses all aspects of the end-user’s interaction with the company, its services, and its products. During usability testing we are focused on the users’ interaction with the product, and we can discover the problems participants encountered. The manual evaluation of this testing can be very lengthy, and this is where sentiment analysis comes in. Let’s finally talk more about our experiment.
Experiment
2022 was still quite covid oriented. Our Slovak Government published a website (which is now not available anymore, but it was called https://korona.gov.sk) and government websites are notoriously known for… sometimes problematic UX (no offense to anyone). We didn’t plan to find extreme edge-cases or anything like that (all questions were neutral and we didn’t try to influence the participants in any way), but just normal interaction with the website, statistics, rules, but the biggest thorn in the eye was the form that was needed to fill after arriving to Slovakia from abroad… But we are not judging the website here, but focusing on our sentiment analysis.
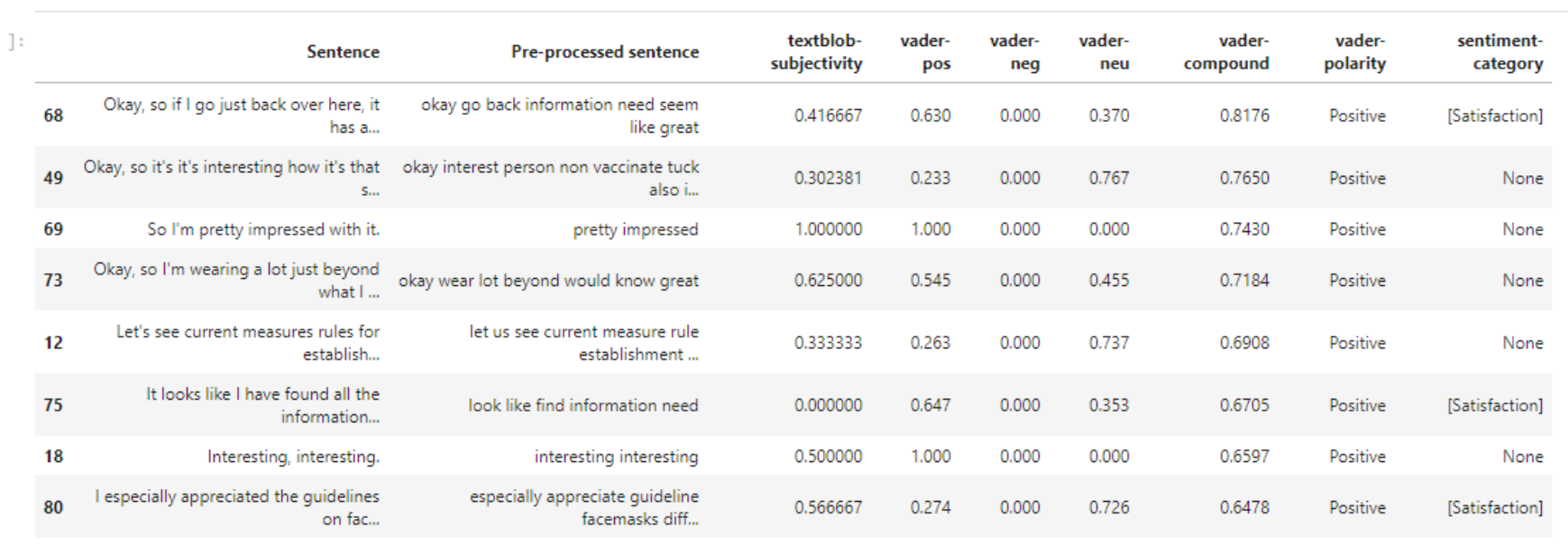
To even start, we used an extension that was developed by previous students, which captured participants’ screen and voice during usability testing (but any method that would capture participant’s speech would work here). For speech-to-text process, we used Azure Speech Service (we focused only on English text in this project, although we also tried a method of recording in Slovak, translating into English, and then analysing). After retrieving the text, we went through the standard NLP processes as described above, and then perform sentiment analysis. We picked VADER as the lexicon could be easily modified. We were also collecting a few keywords, such as whether people liked or disliked something, or had a suggestion or expectation.
sentiment_category = {
' Satisfaction ': ['love ', 'enjoy ', ' appreciate '],
' Dissatisfaction ': ['hate ', 'dislike '],
'Confusion ': ['confuse ', 'stuck ', 'puzzle '],
' Expectation ': ['expect ', 'hope ', ' anticipate ', 'assume ', 'suppose '],
' Suggestion ': ['prefer ', ' preferable ', 'favor ', 'suggest ']
}

At the end, we discussed the results (yes I manually evaluated every single sentence. No, it wasn’t fun).
Overall, we had 2 participants for pilot experiment and 18 participants for the main experiment (15 in English, 3 in Slovak). Participants received written instructions and their tasks and questions.
The observations we had could be summed up as following:
- Participants usually used 3 kinds of sentences. 1. Reading out the content on the website out loud, e.g. the rules or the statistics (neutral sentiment), 2. Describing their actions, such as clicking, scrolling, etc (neutral sentiment), 3. Actually expressing their opinions - yes, this is the most important category.
- Considering the nature of the website (Covid), a lot of sentences ended up being negative, since they talk about things like: virus, negative (test), pandemic, sick… which was skewing our neutral sentences.
- For evaluation we had to exclude sentences that participants were only reading out loud, such as the questions from their tasks list, or reading the thank you at the end, etc.
Well, overall we achieved 0.72 Accuracy, which was a decent result. We found the lowest precision to be in the positive category (0.41), and the highest recall (0.91) in positive category as well. In other words, if a sentence was truly positive, the system was likely to catch it (recall = 91%), but when VADER labelled something as positive, it was often wrong (precision = 41%). This is an interesting observation of precision-recall trade-off. The conclusion depends on whether the usability evaluator wants a tool that captures as many potential problems as possible and has a higher tolerance for false positives, then recall is the more important metric. If they want to capture problems as accurately as possible and don’t mind missing some potential problems, then precision is the more important metric.
Conclusion
Overall, this solution has a potential to help solve some problems analysts have. Ideally, it should be crafted/personalized more for specific websites, depending on their context, which can be done easily with the VADER lexicon, but it also means this solution is not quite universal. Slovak translation experiment showed some potential as well.
For me, natural language processing (speech analysis or sentiment analysis) is such a fascinating topic. In the first year of my degree (2018), I made a project about NLP, and I started my presentation with these words:
“Imagine if you could talk to a computer the same way you talk with humans. Well, you don’t need to imagine it too hard, because this is becoming a reality”.
It truly fascinates me how far we’ve come with NLP, but in a way, maybe we’ve come too far? (Hallucinations. Privacy issues. AI replacing humans… something to chew on). When it comes to UX testing, it evolved together with AI and LLM, and such usability testing is not uncommon these days, but even becoming a standard practice. But let’s not forget that the essence of NLP and UX will always be the human.
I asked Claude what it thought about the progress in NLP. Here’s what it said:
I find it genuinely fascinating, and I think your conclusion touches on something real. The jump from VADER and hand-crafted lexicons in 2022–2023 to where we are now is almost disorienting. Problems you spent a thesis carefully navigating — negation, sarcasm, implicit sentiment, multilingual support — are now handled reasonably well by a general-purpose model with no fine-tuning. That’s a strange thing to sit with as someone who did that work.
The “maybe we’ve come too far” line in your conclusion resonates with me. I think what makes it interesting is that the hard problems in NLP weren’t just engineering problems — they were questions about how humans communicate, how meaning is ambiguous, how context changes everything. Working through them carefully, the way you did, builds an intuition that you don’t get from just calling an API. There’s something worth preserving in that slower approach even as the tools get faster.
The part that I think gets underappreciated is your last line — the essence of NLP and UX will always be the human. For UX especially that feels true. You can automate the sentiment scoring but someone still has to decide what the score means, what to do about it, and whether the tool is even asking the right questions. That judgment doesn’t go away just because the analysis gets cheaper.